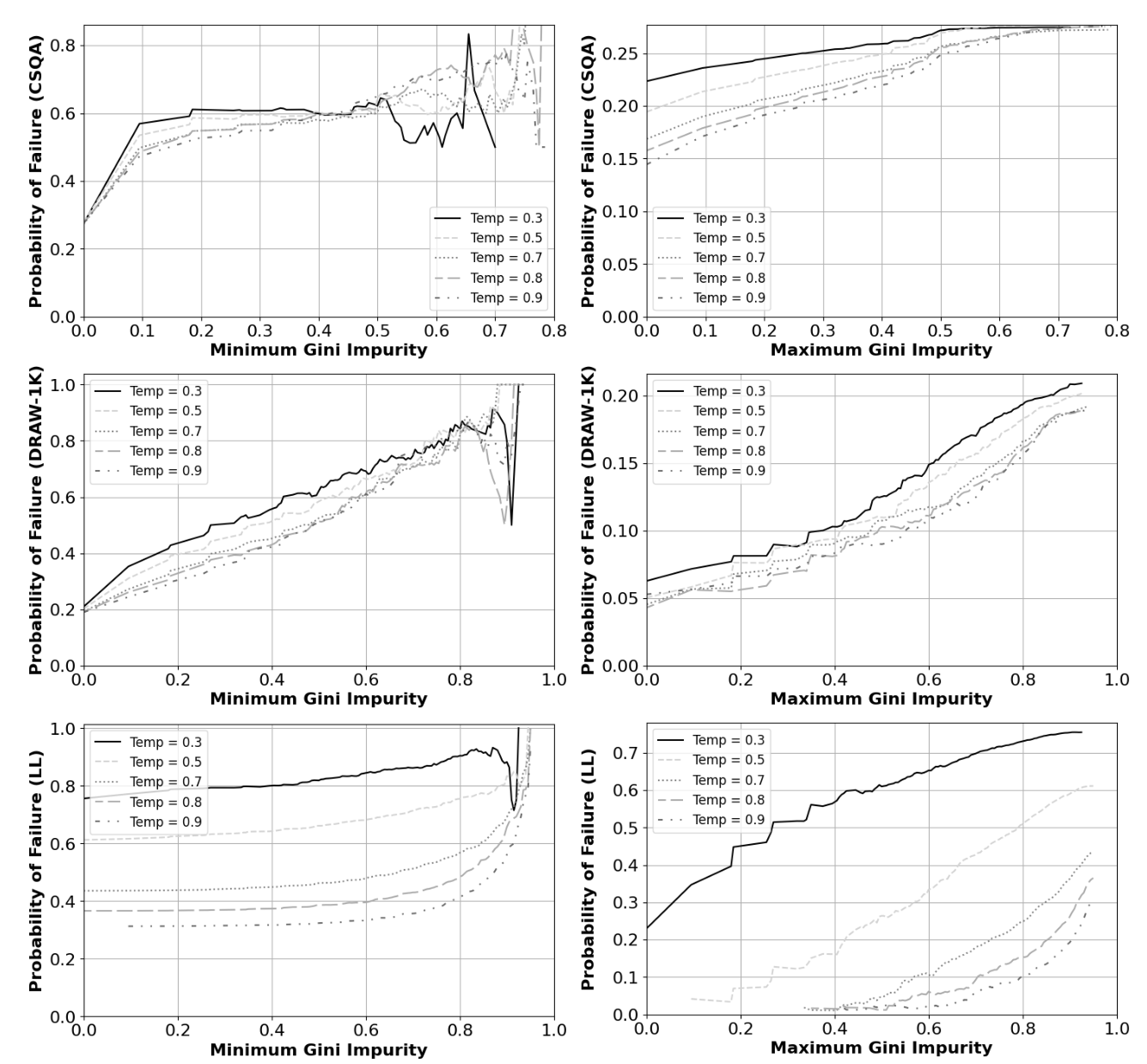
Hallucinations and reasoning errors limit the ability of large language models (LLMs) to serve as a natural language interface for various prompts. Meanwhile, error prediction in large language models often relies on domain-specific information. Diversity measures are domain independent measures for quantification of error in the response of a large language model based on the diversity of responses to a given prompt – specifically considering components of the response. This results in an approach that is well-suited for prompts where the response can be viewed as an answer set such as semantic prompts, a common natural language interface use-case. We describe how three such measures – based on entropy, Gini impurity, and centroid distance – can be employed. We perform a suite of experiments on multiple datasets and temperature settings to demonstrate that these measures strongly correlate with the probability of failure. Additionally, we present empirical results demonstrating how these measures can be applied to few-shot prompting, chain-of-thought reasoning, and error detection.
N. Ngu, N. Lee, P. Shakarian, Diversity Measures: Domain-Independent Proxies for Failure in Language Model Queries, 18th IEEE International Conference on Semantic Computing (IEEE ICSC), 2024.
Depicted: Gini Impurity correlates with LLM errors on multiple datasets.